When I joined Ompractice in early 2021 to rebuild the Ompractice website from the ground up, my daily updates to the team used a lot of nonsensical-sounding terms like git, Django, Swagger, and Postgres. For the non-engineers on my team, it sounded like a bunch of made-up words. So, on one April afternoon, I put aside an hour of my time to take a step back and explain in simpler terms what I was doing and how it works. Specifically, I aimed to demystify something that we all use every day: the Internet. Now, more than a year later, this blog post relays the content of that presentation with all the cheesiness that questionable restaurant and pizza analogies can bring.
What is the Internet?
Before diving into how the Internet works, we first must understand what the Internet is. In the simplest terms, the Internet is a global network of computers talking to one another.
What is a network?
A network is any group of computers that are connected to one another. For example, in an office, there could be a network of computers that exchange information, but they might not necessarily be connected to the Internet. There could also be a government facility somewhere with a network of computers that exchange information but that are not necessarily connected to the outside world. So, when I say Internet with a capital I, what I’m referring to is that global network, of which there is only one, that allows pretty much any computer to talk to any other computer all around the world.
What is a computer?
The computers that constitute the Internet include not just desktop computers but also laptops, mobile phones, and tablet devices. In fact, even “smart devices” like newer thermostats, doorbells, and refrigerators are or have computers that can be connected to the Internet.
One of the most important types of computers to understand in the context of the Internet is called a server. If you’ve ever seen an architecture diagram, you might think of servers as a stack of rectangles with little squares. Or, if you’re into Hollywood movies, maybe you imagine a high-tech, blue-lit data center full of ceiling-high racks of blinking machines without keyboards or monitors. If you’re more of the do-it-yourself type, maybe servers bring to mind a rat’s nest of wires shoved into a closet, quietly driving up your electricity bill.
In reality, a server is not a specific kind of computer. It is not necessarily a Dell or a Mac. Rather, a server is defined by the way the computer is used – or the way the piece of software is used. In its simplest terms, a server is a device or piece of software that is doing work for something else. Servers are the proletariat of computers, doing the hard work for other computers or other software.


The Internet is a Restaurant
Imagine that you are a customer at a restaurant, sitting at a table where you want to eat food that’s being prepared out of sight. As a restaurant patron, you’re the person who is using the computer and who wants to use the Internet.
Servers are the workers in the back kitchen who are preparing food, cooking meals, and washing the dishes and silverware. Servers do a lot of the hard work on the Internet, but you don’t interact directly with them. You benefit from what they do but you don’t actually see them.
Note that where this metaphor gets a little bit tricky is that servers are not the waitstaff, so when I say server, I’m talking about computer servers. And again, when I say computer server, think of people in the back kitchen: the chefs, the line cooks, and the dishwashers.
So who are the restaurant waitstaff? Who is connecting you – the restaurant patron (the computer user) – to the food being prepared by the kitchen staff (the computer servers)? In short, the clients. In terms of the Internet, clients are the computers and devices that you (and other Internet users) are interacting with directly. If you are browsing the Internet on your laptop, then your laptop is the client. If you are using a mobile app, then your phone is the client. If you are ordering grocery deliveries directly through your refrigerator, then your refrigerator is the client.
In this restaurant analogy, clients are the waitstaff who bring you (the computer user) your food (content from the Internet) that is being prepared out of sight by kitchen staff (the servers). They are interacting with you, taking your orders, bringing them to the back of the kitchen, working with the folks preparing your food and later bringing that food back to you. Essentially, the Internet is built on that client-server relationship.



How does this client-server model actually work?
Let’s look at Instagram as an example. When you decide you want to go to Instagram.com, it’s like a restaurant diner deciding on what food they want to order. Your computer, the client, receives your order and then talks to some Instagram servers to request the content you’re looking for. In turn, these servers talk amongst themselves to collect the content that you requested (e.g. cat reels and dog pictures, presumably). This content might be dispersed across multiple servers and include things like the images and videos, the captions, the hashtags, the tagged accounts, the likes, and the comments.
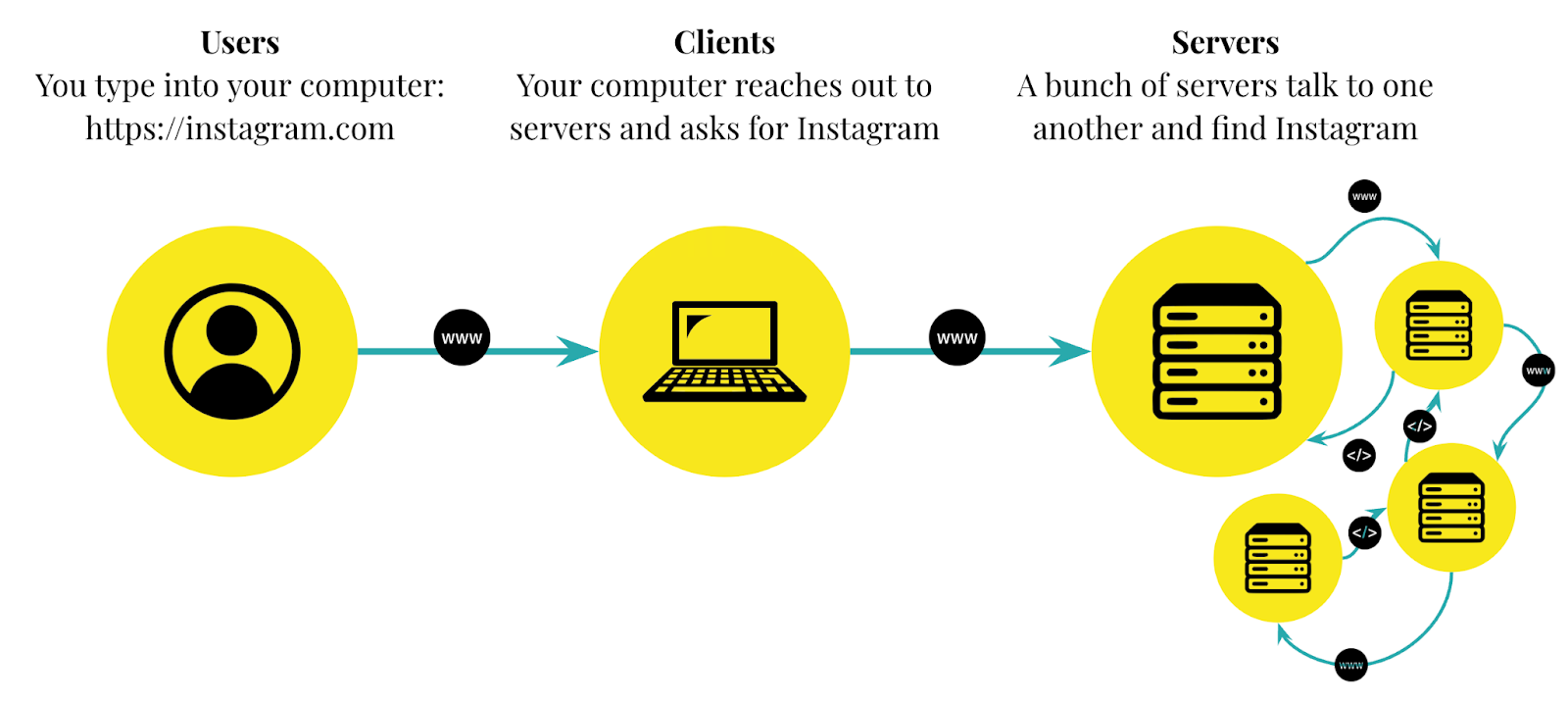
Once this data is all aggregated, the servers return it to your client computer in a response and in turn your computer renders the data to look like the Instagram you know and love.
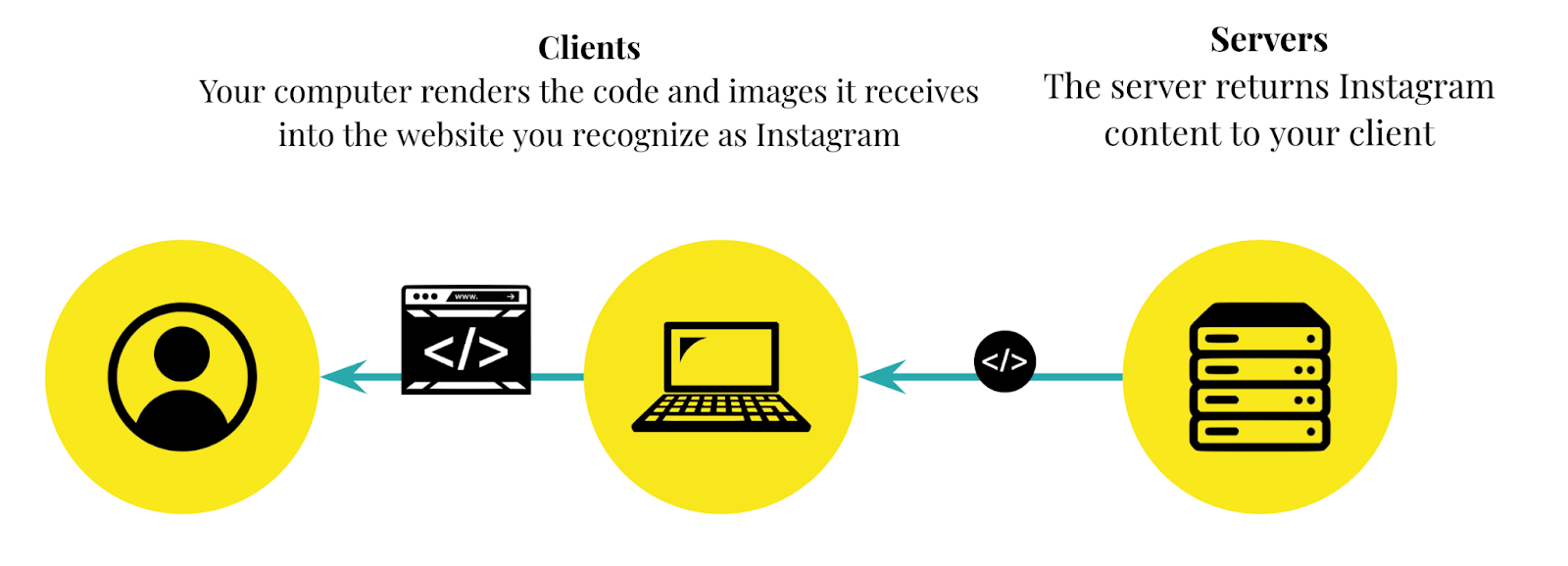
This process then repeats itself every time you interact with the Instagram website. Every time you scroll for new content, make a post, or like or comment on someone else’s, your client computer sends another request to Instagram servers and these servers send a response back which your computer renders into something beautiful and usable.
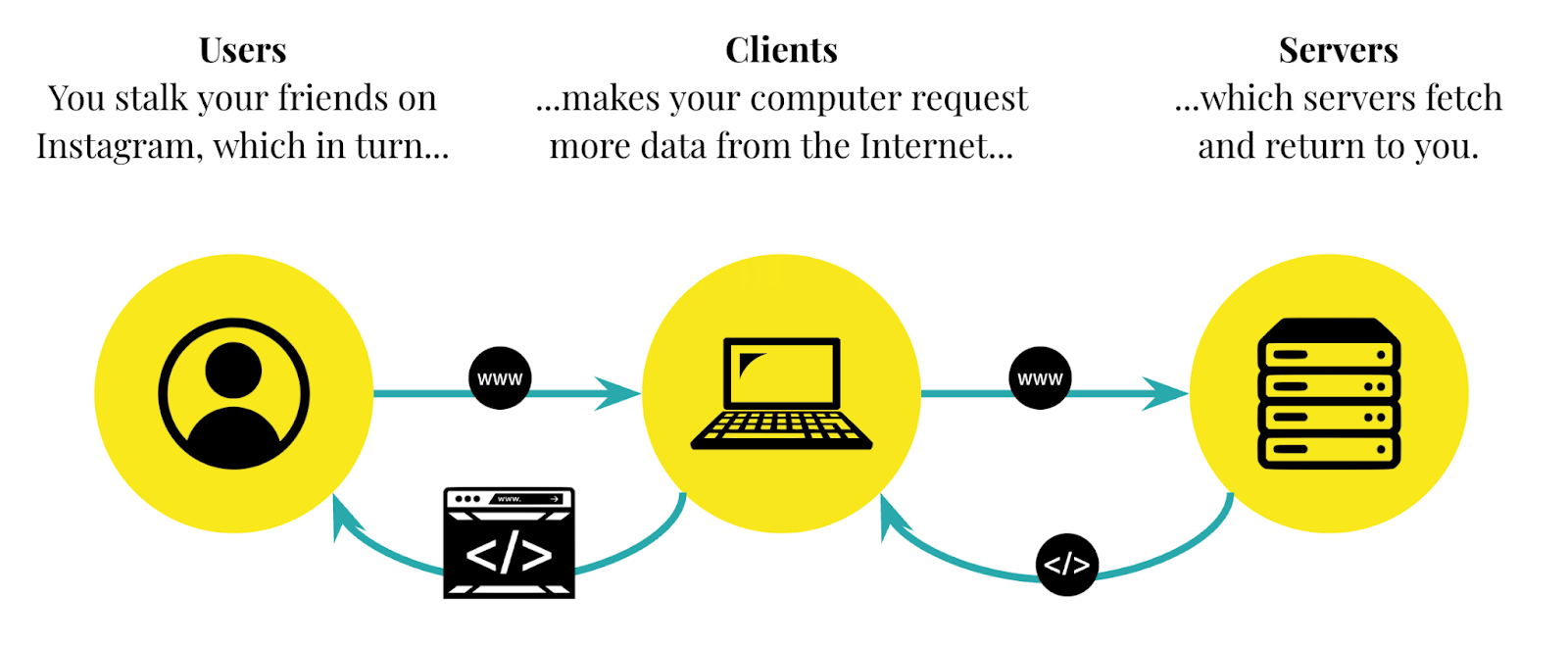
The same thing happens with Ompractice, too. Every time our students (the users) visit the schedule, their phones and laptops (the client computers) make requests to our servers, which in turn return the class list and all related data to be rendered into a teal and white list.
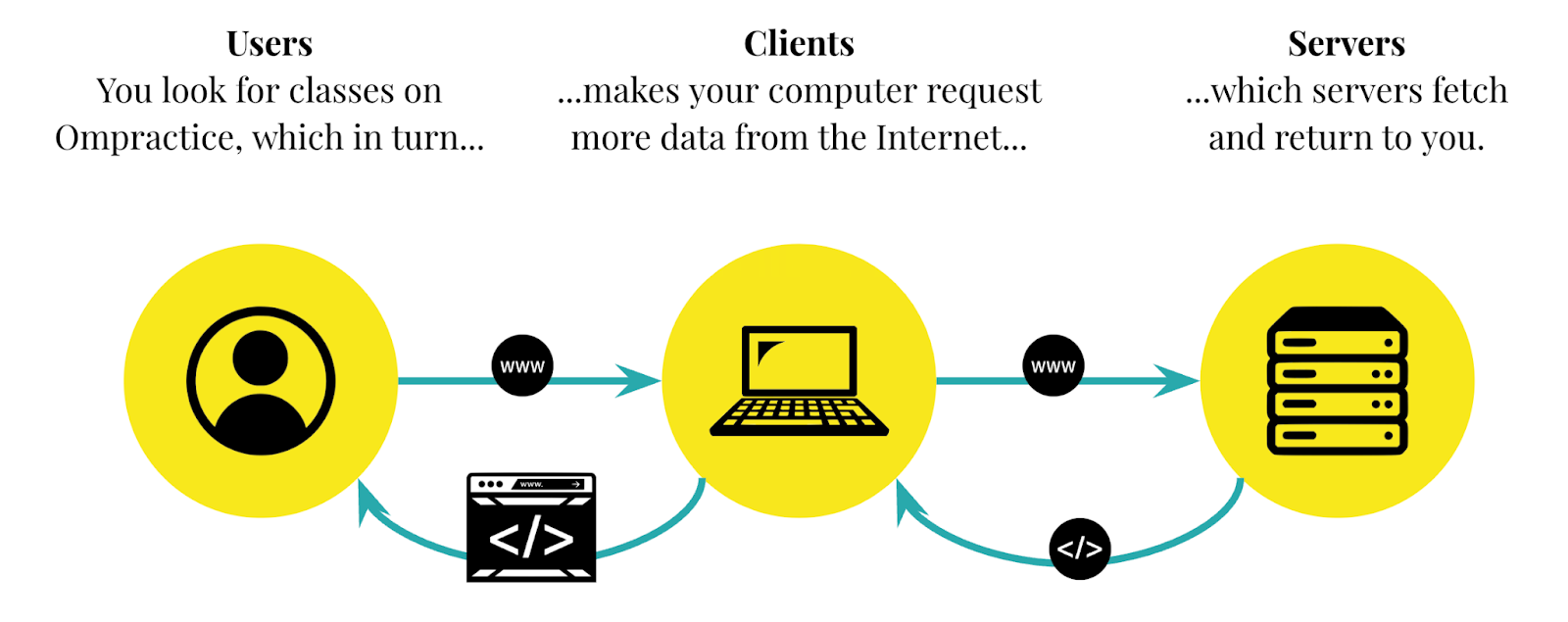
But wait – what if you use a mobile app instead of a computer?
Whether you’re using Safari on your Mac laptop, Chrome on your Android phone, or an app straight from the App Store or Google Play Store, it works the same way. The phone on which you’ve installed the app is still your client device and it’s still sending requests and fetching responses from remote servers. It doesn’t matter whether it’s your computer or your mobile phone or your gaming console or your smart device – if you use it to connect to the Internet, then it’s a client.
Where Does the Code Run?
The web content we access via the Internet – that is, the websites and interactive experiences and applications – are written up in code that our client computers can interpret and render for us. But where is this code actually running? There are two primary places this software can execute:
- Clients: the frontend code will run on the client’s browser (or in an app)
- Servers: the backend code will run on cloud-based servers
What is a browser?
A browser is an application that lets you use the Internet on your computer. Basically, it’s an app whose sole purpose is using the Internet. Common browsers include Google Chrome, Firefox, Safari, and Edge. Often, when developers talk about “frontend code,” they are referring to software that executes in a browser.
What is “the Cloud”?
You’ve probably heard of this nebulous thing called “the cloud” or sometimes even “cloud computing.” Simply put, the cloud is other people’s computers.
No matter what, when you’re using the Internet, there are physical computers somewhere doing computations and storing and serving up data. Basically, if you want to leverage the cloud, you pay another company for computer power without having to worry about maintaining, operating, or eventually replacing those physical computers. You get to benefit from these computers without any of the boring, manual work of keeping them up-to-date and running.

Remember this picture of servers? This is the cloud! Software that runs on the cloud is still running on physical computers in a data center or warehouse somewhere. There’s data centers all over the world run by major companies like Amazon, Google, IBM, and Microsoft as well as much smaller companies that offer competing services, and these data centers are filled with servers – physical computers that are fundamentally acting like computation warehouses. When you’re using the cloud, you don’t care about which specific computer you’re using – whether it’s on the third row in the sixth aisle of building one or not. All you care about is that you have access to reliable computation power and that you don’t need dedicated staff to keep it available.
Without the cloud, you’d have to manage your own server machines somewhere in your office, as pictured below. This often requires dedicated IT staff and means you spend more time considering things like power, software updates, and redundancy and less time actually building things that serve your business.
Who cares about the Cloud?
Let’s dig into the restaurant metaphor again. You, the diner (the person trying to access the Internet) don’t care about the Cloud. You just want to access Instagram or Ompractice and don’t care what’s going on under the hood.
Likewise, your client devices (the waitstaff) don’t care about the Cloud. They just know they need to talk to servers (kitchen staff) and don’t care whether these servers are located in somebody’s basement or in a data warehouse so long as they can fetch the orders (web requests) they need.
In our restaurant metaphor, it’s the restaurant owner – or rather, the business owner – who cares about the Cloud. The company is the restaurant owner who needs to decide whether to manage the kitchen staff themselves (i.e. manage their own server computers in a back closet) or to contract out food preparation (i.e. pay another company for access to cloud computing). As the owner, all they care about is that their recipes are being made and that the food is being prepared so that they can give it to their customers.
As the company, if they go with a Cloud-based approach, they are still responsible for the recipes but they don’t need to worry about hiring, training, and managing chefs, line cooks, or even dishwashers – the contractor will handle that for them. The Cloud equivalent means Ompractice paying Amazon or Google to manage physical computers for us, and we just send them the recipes (code) that those computers should run. They could replace those physical computers, and we would never know or care.
Isn’t the Cloud more complicated than that?
Providing cloud-based services can be very complicated, but most companies only use cloud resources provided by other companies and that’s much easier. This is why big companies offer Cloud services: they can make a lot of money solving this hard problem for other, smaller companies who would rather not focus on these complications.

Frontend versus backend
There’s several ways to define frontend versus backend in the context of web development, and one common way is as follows: Frontend code is the code running in a browser and backend code is the code running on a server. In particular, frontend code often refers to what the user sees and interacts with, whereas backend code includes databases (where information is stored), business logic (how information is manipulated), and APIs (how information is shared with clients).
With regard to the restaurant metaphor, the frontend is the dining area where a customer eats and the backend is the kitchen where food is prepared out of sight.

What about restaurants that cook in front of you (like Hibachi)?
Sometimes code must be written on the frontend and sometimes code must be written on the backend, but a lot of code can be executed on either the client (in a browser) or on the server. In these cases, the web developer must make a choice. Some of the things they will consider include:
- Security: if there is sensitive data, the developer may want to keep it on the server to avoid a user’s malware or a malicious actor from compromising that data.
- Cost to company: moving computation to the browser can reduce server costs (especially if your servers are “in the cloud”).
- Browser load: if the developer pushes too much computation to the client, the user’s browser might start running slowly and the computer fan might kick into high gear as it eats up CPU. The restaurant equivalent to this is someone having the food cooked in front of them at a Hibachi restaurant and then being alarmed when they see the bill at the end of their meal.
How Do Computers Talk to One Another?
So to recap, the Internet is computers talking to one another, where some computers are clients being used directly by the user and some are servers that store, manipulate, and serve information. But this doesn’t answer a fundamental question: how do computers talk to one another? More specifically:
- How do the computers find one another?
- How do they exchange information?
How do computers find one another?
Every computer on a computer network has an IP (Internet protocol) address. An IP address is kind of like a location address as it identifies a location and tells others how to get to it. It’s worth noting that IP addresses have two formats:
- IPv4: 172.16.254.1 (old format)
- IPv6: 2001:db8:0:1234:0:567:8:1 (new format)
However, as an Internet user, you’re unlikely to have ever needed to type in a long string of numbers and letters like this. Rather, you’re probably used to using something called URLs (uniform resource locators). URLs look something like this:
https://app.ompractice.com:443/classes
Where the components are: [protocol]://[subdomain].[domain]:[port]/[resource path]
- Protocol: https (others include http, ftp, smtp); FYI: “https” stands for hypertext transfer protocol secure
- Subdomain: www (for “world wide web”) is pretty common 😉
- Domain name: this is like a nickname for an IP address so users don’t need to type it in! FYI: the “.com” is the TLD, or top-level domain
- Port: human users can typically ignore this (443 is standard for https), but computers talking to one another often need to include this
- Resource path: specifies what information is needed from the other computer
The domain name system (DNS) maps a domain name (like ompractice.com) to an IP address (like 192.124.249.160) so that you don’t need to memorize hard-to-recall IP addresses. Essentially, you can think of DNS as “the phonebook of the Internet.”
You might be wondering, “who names and assigns IP addresses and domain names?” It turns out that there are a slew of organizations that handle these assignments on both the global and local levels, including but not limited to:
- ICANN: Internet Corporation for Assigned Names and Numbers
- IANA: Internet Assigned Numbers Authority
- ISPs: Internet Service Providers
At the top is ICANN, which controls all IP addresses and gives out blocks of IP addresses to different regional groups, which in turn give out blocks of IP addresses to other groups. As you get all the way down the chain, you end up with Internet Service Providers (ISPs), who charge consumers for access to the Internet. It’s typically these ISPs that assign IP addresses to client devices in users’ homes and offices.
How do computers exchange information?
Backend servers use something called APIs (Application Programming Interfaces) to instruct other computers on how to talk to them. APIs define what information a piece of software will provide as well as how it will provide it (i.e. the format of the data). Computer servers usually have API endpoints that they use to share information.
Two common data formats are XML (eXtensible Markup Language) and JSON (JavaScript Object Notation). As you can see in the example below, both formats can encode the same information in a way that is readable by both computers and humans.

If the Internet is a restaurant, then APIs are its menus. APIs, like restaurant menus, enumerate what resources the server can provide. And, like restaurants, you can customize the orders within reason. For example, APIs can provide data in different formats, much in the same way that you can order the same food on a plate for fining-in or in a tupperware for takeout.
When developers are working with APIs, they have several considerations including:
- What “kind” of API is it? For example, RESTful, SOAP, or GraphQL
- How are the API’s access-controlled? For example, basic authentication, API keys, OAuth
- What kind of API documentation exists? For example, Swagger, Redoc, OpenAPI
However, APIs are not the only way by which computers talk to one another, so you don’t always need an API to connect systems. Instead, you can use data transfer mechanisms such as flat file transfers, which allow you to dump a bunch of data to a designated place, like a secure FTP server. This can be done in several ways:
- Automatically, on-demand (“near real-time”)
- Automatically, on a schedule (e.g. every 30 minutes, or once per day)
- Manually, when a human at one company goes through explicit steps to move files around
To Recap…
- The Internet is computers around the globe talking to one another.
- Clients are the computers you use (like laptops and cell phones).
- Servers are computers or software that do work for other computers.
- Clients are like wait staff whereas servers are like kitchen staff.
- Frontend is the code that runs on the client (i.e. your computer) and is like the dining area of a restaurant.
- Backend is the code that runs on the server (i.e. on computers you don’t know or care about) and is like the back kitchen of a restaurant.
- Software developers have some flexibility in where they run their code, whether it’s frontend or backend (think about a Hibachi restaurant).
- The frontend (client computers) use URLs with domain names to send requests to servers.
- The DNS maps the domain name to an IP address to find the intended servers on the backend.
- For each request sent, the frontend (client computers) receive a response from the server.
- Computers communicate with APIs (which are like menus) and can also use data transfers, which may or may not be real-time.
- Some servers live in the cloud, which means third-parties manage those computers.